Interface de Preparação
Esta página apresenta a interface de Preparação, a etapa do pipeline que converte documentos importados em segmentos analisáveis. Ela define a unidade de processamento, aplica normalizações opcionais e materializa sentenças ou tokens para a etiquetagem.
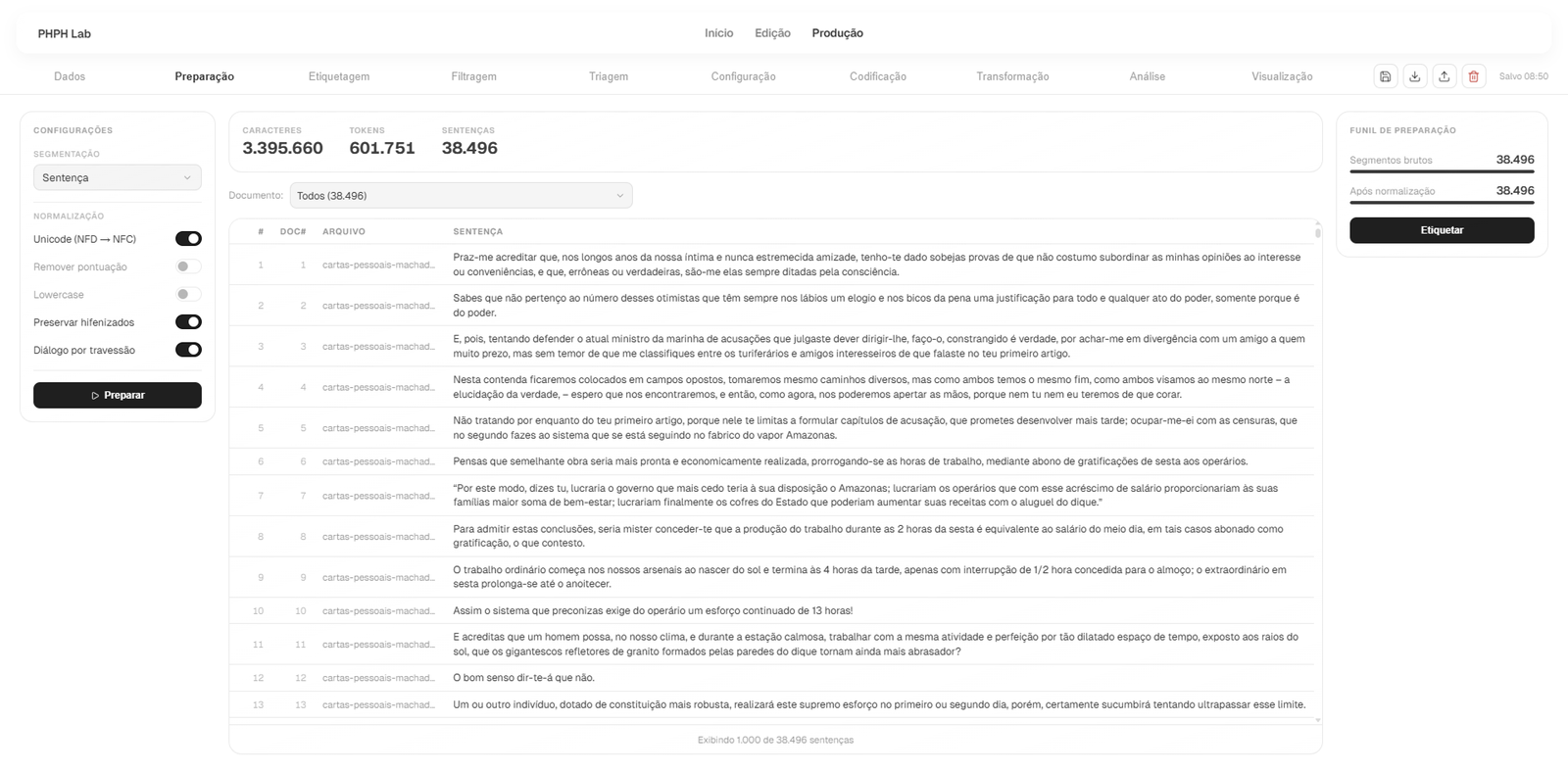
No contexto da Produção, Preparação funciona como a ponte entre corpus bruto e análise linguística: o texto ainda preserva vínculo documental, mas passa a ser dividido e normalizado conforme as decisões do pesquisador. A interface se aplica quando os documentos já foram importados e precisam de unidade estável; configure segmentação, Unicode, pontuação, caixa, hifens e diálogos; use a tabela filtrada para validar exemplos antes de enviar para etiquetagem.
Resumo técnico
| Aspecto | Referência |
|---|---|
| O que é | Etapa de segmentação e normalização do corpus. |
| O que faz | Gera sentenças ou tokens e aplica regras textuais controladas. |
| Como funciona | Processa documentos do snapshot e grava segmentos preparados. |
| Aplicação | Definir a unidade linguística que será etiquetada e filtrada. |
| Configuração | Escolha segmentação e regras de normalização. |
| Uso | Configure opções, clique em Preparar, revise segmentos e avance para Etiquetar. |
Controles
| Campo ou controle | Função |
|---|---|
| Segmentação | Sentença ou Token. |
| Unicode (NFD -> NFC) | Normaliza composição Unicode. |
| Remover pontuação | Remove pontuação do segmento. |
| Lowercase | Converte segmentos para minúsculas. |
| Preservar hifenizados | Mantém hifens quando a pontuação é removida. |
| Diálogo por travessão | Segmenta linhas de diálogo iniciadas por travessão. |
| Preparar | Materializa os segmentos. |
| Documento | Filtra a tabela por documento. |
| Etiquetar | Envia segmentos para a etapa de etiquetagem. |